

From SQL Server 2012, we can now define columnstore indexes on our database tables. The in-memory columnstore index stores data in a column-wise (columnar) format, unlike the traditional B-tree structures used for clustered and non-clustered rowstore indexes, which store data row-wise (in rows). A columnstore index use a column-based storage model, as well as a new ‘batch mode’ of query execution and can offer significant performance gains for queries that summarize large quantities of data.
Demo
In your OLTP database, you might have a few reports that are slow, because they draw from very large tables.
In our example, we have a table dbo.TAT_TIME in our database with more than 25 million records.
Let’s see how we can benefit from columnstore indexes.
To see the benefit of columnstore indexes, let’s compare performance of the same query with and without a columnstore index.
SELECT t.TK_EMPL_UNO, t.WIP_STATUS, COUNT(1) AS NumTimeEntries, SUM(t.BASE_HRS) AS BASE_HRS, SUM(t.TOBILL_HRS) AS TOBILL_HRS, SUM(t.BILLED_HRS) AS BILLED_HRS FROM dbo.TAT_TIME AS t INNER JOIN dbo.HBM_MATTER AS m ON t.MATTER_UNO = m.MATTER_UNO GROUP BY t.TK_EMPL_UNO, t.WIP_STATUS ORDER BY t.TK_EMPL_UNO, t.WIP_STATUS;
This query retrieved 22220 rows with the execution time of 2 minutes and 43 seconds, since the dbo.TAT_TIME table has over 25 million rows and this query has to scan the entire clustered index.
Creating the Columnstore Index
Columnstore indexes come in two flavours: clustered and non-clustered. In SQL Server 2012, only non-clustered columnstore indexes are available. The clustered version has been added in SQL Server 2014. For our example, let’s create a non-clustered columnstore index as shown below.
CREATE NONCLUSTERED COLUMNSTORE INDEX NCI_TAT_TIME_TEST ON dbo.TAT_TIME ([TIME_UNO] ,[SOURCE] ,[IMPORT_NUM] ,[ENTRY_STATUS] ,[PRINTED] ,[WIP_STATUS] ,[ACTIVITY_COUNT] ,[MATTER_UNO] ,[ENTRY_EMPL_UNO] ,[TK_EMPL_UNO] ,[RANK_CODE] ,[TOBILL_EMPL_UNO] ,[BILLED_EMPL_UNO] ,[AU_EMPL_UNO] ,[ACTION_CODE] ,[PHASE_CODE] ,[TASK_CODE] ,[LOCATION_CODE] ,[NAR_TEXT_ID] ,[PB_TEXT_ID] ,[TRAN_DATE] ,[POST_DATE] ,[LATEST_PERIOD] ,[BASE_HRS] ,[TOBILL_HRS] ,[BILLED_HRS] ,[CALC_WIP] ,[RATE_METHOD] ,[BASE_AMT] ,[TOBILL_AMT] ,[BILLED_AMT] ,[STD_AMT] ,[HOLD_DATE] ,[TAXABLE] ,[BILL_PRINT] ,[BILLABLE_FLAG] ,[BILL_TRAN_UNO] ,[CURRENCY_CODE] ,[OFFC] ,[DEPT] ,[PROF] ,[BILL_SORT_SEQ] ,[ADJ_CODE] ,[ADJ_AU_EMPL_UNO] ,[ADJ_DE_EMPL_UNO] ,[TRANSFERRED] ,[UNSETTLED_BAL] ,[MERGE_TIME_UNO] ,[IS_WIP] ,[TRANS_MOD_UNO] ,[START_TIME] ,[ACTIVITY_CODE] ,[DRUNO] ,[PHTASK_UNO] ,[ORIGTASK_NUM] ,[BILLED_TAX_AMT] ,[BILLED_TAX_PCT] ,[PERIOD] ,[DOE_STATUS] ,[DISB_UNO] ,[SPLIT_NUM] ,[PA_SESSION_UNO] ,[PA_MOD_COUNT] ,[PROJ] ,[ADMIN_EDITOR_REVIEWED] ,[SUPER_EMPL_UNO] ,[WORKING_TKPR] ,[NEEDS_UI_VALIDATION] ,[HAS_ERRORS] ,[CREATED_DATE_ORIG] ,[RETAINED_BILLED_AMT] ,[RETAINED_BILLED_HRS] ,[GROSS_AMT] ,[ADV_PREMDISC_AMT] ,[CTS_PREMDISC_AMT] ,[DELAYED_SPLIT_NUM] ,[LAST_MODIFIED]);
When I now run the same query again, I get the same results as before, but the results are returned almost instantaneously. The query now finishes in about one second.
Row-oriented storage vs Column-oriented storage
In a row-oriented storage, when SQL Server has to store the data, it will start by writing all columns of the first row to a page. Then if there is enough space, the second row will be added to the same page, and so on until the page is full. And then a new page is allocated and the process continues.
This storage structure is ideal for OLTP workloads. If you need to insert a row, delete a row, or update a row, you make all changes on just a single page in the data file. And queries that are selective enough to return only a few rows usually also touch only a single page, or two pages in the worst case.
In a columnstore index, data is stored on the same 8K pages that SQL Server has been using since SQL Server 7.0. But instead of filling these pages with complete rows, a columnstore index isolates all values for a single column and stores them in one or more pages. The data of the other columns then go into different pages.
This storage structure is ideal for reporting and analytical processing. In a data warehouse (DW), most tables have dozens of columns (at least), and most queries select only a few of those columns.
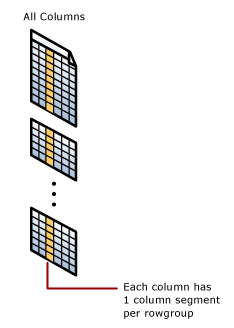
rowgroup
A row group is a group of rows that are compressed into columnstore format at the same time. A rowgroup usually contains the maximum number of rows per rowgroup which is 1,048,576 rows.
For high performance and high compression rates, the columnstore index slices the table into groups of rows, called rowgroups, and then compresses each rowgroup in a column-wise manner.
Column Segment
A column segment is a column of data from within the rowgroup.
- Each rowgroup contains one column segment for every column in the table.
- Each column segment is compressed together and stored on physical media.
Columnstore Compression
Data stored in a columnstore index is always compressed. And the effectiveness of compression achieved for columnstore indexes is extremely high. Data read from a single column is more homogenous than data read from rows, and the more similar the data, the easier it is to compress.
And the more effectively you can compress your data, the more data you can fit on a single page and the more data you can pull into memory, both of which lead to a lower I/O costs.
Batch Mode
The better performance with columnstore indexes is achieved by using “batch mode execution”. It is designed to remove a lot of overhead and optimized to take optimal advantage of the characteristics of modern hardware where you will get the performance benefit that results from the I/O reduction of a columnstore index.
Batch mode processing can operate on multiple rows at a time-a batch stored in an internal memory structure in a format very similar to the on-disk storage format of columnstore indexes rather than one row at a time, as is typical with row-mode processing.
Let’s have a look at the execution plan of the query.
You can notice that the “Estimated Execution Mode” and “Actual Execution Mode” properties of the operators that process the most data of a query running in batch mode and storage as Columnstore. You can see how many batches were used in the “Actual Number of Batches” property, all rows were combined into 134585 batches. A huge saving when compared to the execution in row mode.
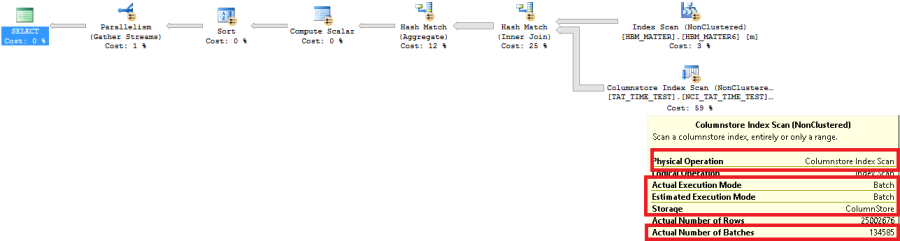
The actual number of rows in a batch is based on two factors: the amount of data that has to be stored for each row (adding more columns to the query will reduce the batch size), and the hardware you are running on (on a system with a larger CPU cache, more rows can be stored in a batch).
Clustered Columnstore Index
A clustered columnstore index is the physical storage for the entire table. No column list can be specified for a clustered columnstore index. But a sort order (ASC or DESC) cannot be specified, since columnstore indexes do not store the data in ordered fashion.
Non-Clustered Columnstore Index
A non-clustered columnstore index and a clustered columnstore index function the same. It contains a copy of a subset of columns, up to and including all of the columns in the table.
Why should I use a Columnstore Index?
A columnstore index can provide a very high level of data compression, typically 10x, to reduce your data storage cost significantly. Plus, they offer better performance than a B-tree index.
Reasons why columnstore indexes are so fast:
- Columns store values from the same domain and commonly have similar values, which results in high compression rates. This minimizes or eliminates IO bottleneck in your system while reducing the memory footprint significantly.
- High compression rates improve query performance by using a smaller in-memory footprint. In turn, query performance can improve because SQL Server can perform more query and data operations in-memory.
- Batch execution improves query performance, typically 2-4x, by processing multiple rows together.
- Queries often select only a few columns from a table, which reduces total I/O from the physical media.
When should I use a Columnstore Index?
Recommended use cases:
- Use a clustered columnstore index to store fact tables and large dimension tables for data warehousing workloads. This improves query performance and data compression by up to 10x.
- Use a non-clustered columnstore index to perform analysis in real-time on an OLTP workload.
How do I choose between a Rowstore Index and a Columnstore Index?
Rowstore indexes perform best on queries that seek into the data, searching for a particular value, or for queries on a small range of values. Use rowstore indexes with transactional workloads since they tend to require mostly table seeks instead of table scans.
Columnstore indexes give high performance gains for analytic queries that scan large amounts of data, especially on large tables.
Beginning with SQL Server 2016 (13.x), you can create an updatable non-clustered columnstore index on a rowstore table. The columnstore index stores a copy of the chosen columns so you do need extra space for this but it will be compressed on average by 10x. By doing this, you can run analytics on the columnstore index and transactions on the rowstore index at the same time. The column store is updated when data changes in the rowstore table, so both indexes are working against the same data.
Beginning with SQL Server 2016 (13.x), you can have one or more non-clustered rowstore indexes on a columnstore index. By doing this, you can perform efficient table seeks on the underlying columnstore. Other options become available too. For example, you can enforce a primary key constraint by using a UNIQUE constraint on the rowstore table. Since a non-unique value will fail to insert into the rowstore table, SQL Server cannot insert the value into the columnstore.
Summary
Columnstore indexes are intended to be used with large tables. There is no hard minimum size, but as a rule of thumb, I would say that you need at least tens of millions of rows in a single table to get real benefit from columnstore indexes.
The only way to evaluate how useful a columnstore index is for a specific database is to compare performance with and without the columnstore index. Adding the query hint OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) to a query will instruct the optimizer to execute the query as if the non-clustered columnstore index does not exist.
The performance benefit available by using columnstore indexes is caused by two major factors. One is the I/O savings caused by the new index structure, the other is batch mode execution.
It uses column-based data storage and query processing to achieve up to 10x query performance gains over traditional row-oriented storage, and up to 10x data compression over the uncompressed data size.
References
https://msdn.microsoft.com/en-us/library/gg492088(v=sql.120).aspx
