

We will be constantly inserting new rows, and updating or deleting existing rows in our columnstore indexed tables. If you think about what this means for a columnstore index, you will realize that this comes with some unique challenges.
Inserting Data
When thinking about adding data to an existing columnstore, depending on the compression algorithms used, it might be necessary to first process all prior values in a segment before the new value can be added. These actions would make the insert very slow. Also, once the last rowgroup reaches its maximum size, a new rowgroup would have to be opened, and the compression methods to be used for its segments would have to be decided based on possibly just a single row to be inserted – this will never result in optimal choices!
Deltastore
To reduce fragmentation of the column segments and improve performance, the columnstore index uses an extra storage area that you can think of as a temporary holding area (deltastore) where new data is stored until sufficient rows have been collected to justify the effort of converting them to the columnstore format. The data in the deltastore is not stored in column oriented fashion, but in a B-tree structure, the same format used for traditional row oriented indexes. The deltastore operations are handled behind the scenes. To return the correct query results, the clustered columnstore index combines query results from both the columnstore and the deltastore.
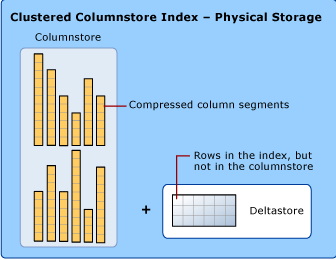
Trickle Insert vs Bulk Load
Let’s examine the effect of trickle insert and bulk load by inserting different numbers of rows in a single INSERT statement, let’s now run the code below. I first insert a large number of rows (150,000) at once, followed by a smaller number of rows (5).
-- Add 150,000 rows INSERT dbo.BLT_BILL_TEST SELECT TOP(150000) * FROM dbo.BLT_BILL; -- Add 5 rows INSERT dbo.BLT_BILL_TEST SELECT TOP(5) * FROM dbo.BLT_BILL;
The output of the metadata query below reveals some interesting results.
SELECT OBJECT_NAME(rg.object_id) AS TableName, i.name AS IndexName, i.type_desc AS IndexType, rg.row_group_id, rg.state, rg.state_description, rg.total_rows, rg.deleted_rows, rg.size_in_bytes FROM sys.column_store_row_groups AS rg INNER JOIN sys.indexes AS i ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE i.type IN (5, 6) -- 5 = Clustered columnstore index. 6 = Nonclustered columnstore index. ORDER BY TableName, IndexName, rg.partition_number, rg.row_group_id;

During a large bulk load, most of the rows go directly to the columnstore without passing through the deltastore. Some rows at the end of the bulk load might be too few in number to meet the minimum size of a rowgroup which is 102,400 rows. When this happens, the final rows go to the deltastore instead of the columnstore. Any insert of 102,399 or fewer rows is considered a “trickle insert”. For “trickle insert”, all of the rows go directly to the deltastore. These rows are added to an open deltastore if one is available (and not locked), or else a new deltastore rowgroup is created for them.
As you can see, the 150,000 rows that were added in the first query were inserted into a new rowgroup, and this rowgroup has state 3 (COMPRESSED), indicating that this rowgroup is not a deltastore but a regular columnstore rowgroup. The 5 rows of the second insert were then added to the open deltastore rowgroup.
Bulk loading is the most performant way to move data into a columnstore index because it operates on batches of rows. Bulk loading fills rowgroups to maximum capacity and compresses them directly into the columnstore.
To perform a bulk load, you can use tools like bcp utility, the ‘fast-load’ option with Integration Services (SSIS) OLEDB destination, or the T-SQL BULK INSERT statement or select rows from a staging table.
When designing a load process that adds a lot of data, make sure that the bulk load method is used to ensure the majority of data is bulk loaded, and only small amounts of rows are trickle inserted in the deltastore. Reading a single deltastore when processing a columnstore index will not significantly affect performance.
Deleting Data
Let’s examine the effect of deleting data from a columnstore index, let’s now run the following code.
-- Delete ten percent of the rows, throughout all rowgroups DELETE FROM dbo.BLT_BILL_TEST WHERE [TRAN_UNO] % 10 = 0;
Let’s examine the output of the metadata query below.
SELECT OBJECT_NAME(rg.object_id) AS TableName, i.name AS IndexName, i.type_desc AS IndexType, rg.row_group_id, rg.state, rg.state_description, rg.total_rows, rg.deleted_rows, rg.size_in_bytes FROM sys.column_store_row_groups AS rg INNER JOIN sys.indexes AS i ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE i.type IN (5, 6) -- 5 = Clustered columnstore index. 6 = Nonclustered columnstore index. ORDER BY TableName, IndexName, rg.partition_number, rg.row_group_id;

You can notice the deleted_rows column from the above result. These rows were not actually deleted from the columnstore index. Instead, SQL Server simply marks the row as deleted without removing any data. The data returned by the DMV query reflects this method of logically deleting the data without physically removing it – the total_rows of the rowgroups has not been changed, because all the rows are still there; the deleted_rows column tells us how many of these rows are no longer valid.
When rows in a columnstore index have to be marked as deleted, an extra storage structure is added to the index. This storage structure is often referred to as the “Deleted Bitmap”. The delete marks are stored in an internal, row-compressed B-tree, as a virtual two-column table storing only rowgroup number and row number of the row within that rowgroup.
Updating Data
When rows in a columnstore are updated, updating data can be considered as equivalent to deleting the old version of the data and inserting the new data. Not the rows that are still in a deltastore: these are still in a B-tree, so they can easily be processed by the regular update mechanism. But for the rows that are already compressed in columnstore rowgroups, every update is processed by marking the old row as deleted and trickle inserting the new data in a deltastore.
Let’s see this in action by running the following code which updates about 10% of the data in the table.
-- Update ten percent of the rows, throughout all rowgroups UPDATE dbo.BLT_BILL_TEST SET RELEASED = 'N' WHERE [TRAN_UNO] % 5 = 0;
Let’s examine the output of the metadata query below.

If you observe the results, you can notice that there are now many rows marked as deleted in the compressed rowgroups. You can also see one open rowgroup, the result of adding over 158k “new” (updated) rows as trickle inserts into the deltastore.
Columnstore Indexes – Defragmentation
For columnstore index maintenance, there are two options: Reorganize and Rebuild are available.
Reorganizing the Columnstore Index
Reorganizing a clustered columnstore index can be useful after doing a large data load that did not use bulk load, or after doing a large update – in short, after any operation that causes a lot of trickle inserts. Trickle inserts go into an open deltastore, which will be closed when it reaches 1,048,576 rows. At that point, without further action, it will wait for the background tuple mover process to pick it up and compress it into columnstore format. Until it catches up, you can experience suboptimal performance from your columnstore index.
When you reorganize the index, you tell SQL Server to not wait for the tuple mover, but immediately compress all closed deltastore rowgroups for the specified index. Reorganizing a columnstore index is an online operation, which means that the index can be used normally during the process.
The tuple mover will any how kick in few minutes and done the same work in the background. You only have to reorganize a clustered columnstore index if there is a reason why you need the closed rowgroups to be compressed immediately.
Starting with SQL Server 2016 (13.x) the reorganize operation will also remove rows that have been deleted from the columnstore.
Let’s see the reorganize operation of a clustered columnstore index in action. Run the following code to reorganize the clustered columnstore index. Before and after the reorganize, it queries the rowgroup metadata;
SELECT OBJECT_NAME(rg.object_id) AS TableName, i.name AS IndexName, i.type_desc AS IndexType, rg.row_group_id, rg.state, rg.state_description, rg.total_rows, rg.deleted_rows, rg.size_in_bytes FROM sys.column_store_row_groups AS rg INNER JOIN sys.indexes AS i ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE i.type IN (5, 6) -- 5 = Clustered columnstore index. 6 = Nonclustered columnstore index. ORDER BY TableName, IndexName, rg.partition_number, rg.row_group_id; -- Reorganize the index ALTER INDEX CCI_BLT_BILL_TEST ON BLT_BILL_TEST REORGANIZE; SELECT OBJECT_NAME(rg.object_id) AS TableName, i.name AS IndexName, i.type_desc AS IndexType, rg.row_group_id, rg.state, rg.state_description, rg.total_rows, rg.deleted_rows, rg.size_in_bytes FROM sys.column_store_row_groups AS rg INNER JOIN sys.indexes AS i ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE i.type IN (5, 6) -- 5 = Clustered columnstore index. 6 = Nonclustered columnstore index. ORDER BY TableName, IndexName, rg.partition_number, rg.row_group_id;
As you can see the results below, the reorganize operation reduced the number of rowgroups from 5 to 3, and saved 14.5 MB of storage. While it may appear as if the number of rows has gone down, this is not actually the case – just remember that the reported number of rows in compressed rowgroups includes the rows that are marked as deleted.

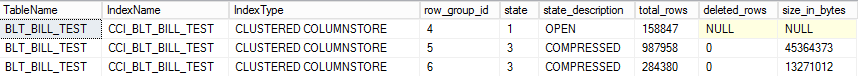
Rebuilding the Columnstore Index
For SQL Server 2016 (13.x) and later, rebuilding the columnstore index is usually not needed since REORGANIZE performs the essentials of a rebuild in the background as an online operation.
To rebuild a columnstore index, SQL Server acquires an exclusive lock on the table or partition while the rebuild occurs. The data is “offline” and unavailable during the rebuild. It re-compresses all data into the columnstore. Two copies of the columnstore index exist while the rebuild is taking place. When the rebuild is finished, SQL Server deletes the original columnstore index.
Rebuilding the entire table takes a long time if the index is large, and it requires enough disk space to store an additional copy of the index during the rebuild. Consider rebuilding a partition instead of the entire table. For partitioned tables, you do not need to rebuild the entire columnstore index because fragmentation is likely to occur in only the partitions that have been modified recently. While rebuilding, for a partitioned table, you can use the ON PARTITIONS clause to specify individual partitions.
Conclusion
Over time, modifications to data in a columnstore index will deteriorate its usefulness. Rows marked as deleted still take up space, trickle inserts and small bulk loads will not compress as effectively, and the global dictionary will never change after the initial index build; all this impacts the compression ratio, resulting in more IOs for the same query. Index maintenance is required in order to periodically restore the index to optimum usefulness.
References
https://docs.microsoft.com/en-us/sql/tools/bcp-utility?view=sql-server-2017





