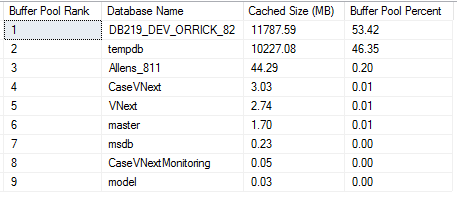
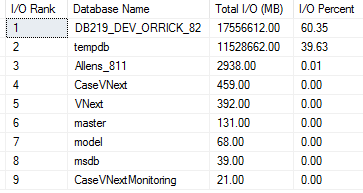
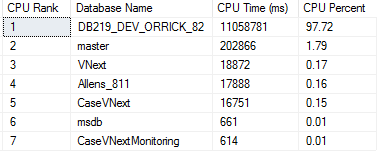
Adding indexes on a database has its own pros and cons. The selection of the right indexes for a database and its workload is a complex balancing act between query speed and update cost. In most of the scenarios developers/administrators underestimate the impact of adding indexes. Without considering all the factors, they often create indexes by assuming that the performance gains outweigh the losses. At the end, without their knowledge they may end up in introducing duplicate indexes which utilizes SQL Server resources and generate unnecessary overhead, causing poor database performance.
The other big issue with indexes that are not required is that they take up space, in both memory and disk space. For databases with very large tables (millions of rows), additional indexes can take Gigabytes of additional space.
Index Usage
While troubleshooting performance issues on the queries, in most of the real world scenarios developers/administrators improve their performance by adding new indexes on the underlying tables, however, in real world usage, the actual index that is used is different to the one they have added or the query that they have optimized is used very infrequently, and not nearly as often as they think.
Let’s figure out the indexes that aren’t used from the SQL Server DMV (Dynamic Management View) that is updated with the usage stats of the indexes.
This query will give you a list of all the indexes in the current database, what tables they are on, and how many times they’re been searched, how many times they’ve been updated, and the size in memory.
SELECT
sch.name + '.' + t.name AS [TableName],
i.name AS [IndexName],
i.index_id AS [IndexId],
i.type_desc AS [IndexType],
ISNULL(user_updates,0) AS [TotalWrites],
ISNULL(user_seeks + user_scans + user_lookups,0) AS [TotalReads],
ISNULL(user_updates,0) - ISNULL((user_seeks + user_scans + user_lookups),0) AS [Difference],
s.last_user_seek AS [LastUserSeek],
s.last_user_scan AS [LastUserScan],
s.last_user_lookup AS [LastUserLookup],
p.reserved_page_count * 8.0 / 1024 AS [SpaceInMB]
FROM sys.indexes AS i WITH (NOLOCK)
LEFT OUTER JOIN sys.dm_db_index_usage_stats AS s
WITH (NOLOCK) ON s.object_id = i.object_id AND i.index_id = s.index_id
AND s.database_id=db_id() AND objectproperty(s.object_id,'IsUserTable') = 1
INNER JOIN sys.tables
AS t WITH (NOLOCK) ON i.object_id = t.object_id
INNER JOIN sys.schemas
AS sch WITH (NOLOCK) ON t.schema_id = sch.schema_id
LEFT OUTER JOIN sys.dm_db_partition_stats AS p
WITH (NOLOCK) ON i.index_id = p.index_id and i.object_id = p.object_id
ORDER BY [TableName], [indexname]
Output
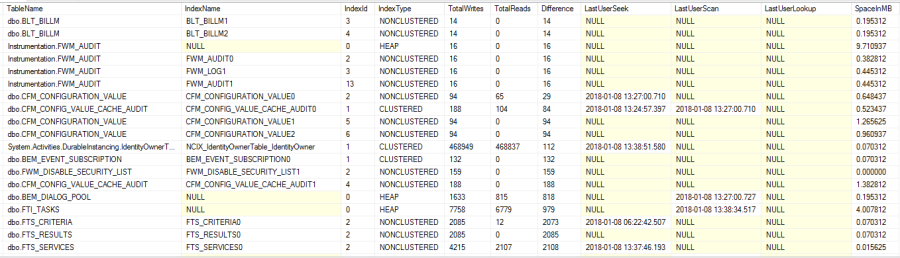
From the output of this query look for indexes with high numbers of writes and zero or very low numbers of reads. Consider your complete workload, and how long your instance has been running and investigate further before dropping an index.
Redundant Indexes
The next most common scenario is that people adding indexes as the application matures, without analysing the old indexes to see if there are superfluous ones due to the new ones that have been added.
Examples
- Two Indexes with the same fields but different included columns.
- A second Index with additional columns. Index 1 is created on column 1 and column 2, then Index 2 is created on column 1, column 2 and column 3.
Reverse Indexes
Two Indexes on the same columns but in different order.
Example
- Index 1 is created on column 1 and column 2, then Index 2 is created on column 2 and column 1.
This query will give you a list of all possible duplicate indexes based on the columns in the current database, what tables and columns they are on.
/* This script will generate two reports that give high level
view of the indexes in a particular database. The sections are as follows:
- Lists any tables with potential Redundant indexes
- Lists any tables with potential Reverse indexes
*/
-- Create a table variable to hold the core index info
DECLARE @AllIndexes TABLE (
[Table ID] [int] NOT NULL,
[Schema] [sysname] NOT NULL,
[Table Name] [sysname] NOT NULL,
[Index ID] [int] NULL,
[Index Name] [nvarchar](128) NULL,
[Index Type] [varchar](12) NOT NULL,
[Constraint Type] [varchar](11) NOT NULL,
[Object Type] [varchar](10) NOT NULL,
[ColName] [nvarchar](2078) NULL,
[ColName1] [nvarchar](128) NULL,
[ColName2] [nvarchar](128) NULL,
[ColName3] [nvarchar](128) NULL,
[ColName4] [nvarchar](128) NULL,
[ColName5] [nvarchar](128) NULL,
[ColName6] [nvarchar](128) NULL,
[ColName7] [nvarchar](128) NULL,
[ColName8] [nvarchar](128) NULL,
[ColName9] [nvarchar](128) NULL,
[ColName10] [nvarchar](128) NULL
)
-- Load up the table variable with the index information to be used in follow on queries
INSERT INTO @AllIndexes
([Table ID],[Schema],[Table Name],[Index ID],
[Index Name],[Index Type],[Constraint Type],[Object Type]
,[ColName],[ColName1],[ColName2],[ColName3],
[ColName4],[ColName5],[ColName6],[ColName7],[ColName8],
[ColName9],[ColName10])
SELECT o.[object_id] AS [Table ID] ,u.[name] AS [Schema],o.[name] AS [Table Name],
i.[index_id] AS [Index ID]
, CASE i.[name]
WHEN o.[name] THEN '** Same as Table Name **'
ELSE i.[name] END AS [Index Name],
CASE i.[type]
WHEN 1 THEN 'CLUSTERED'
WHEN 0 THEN 'HEAP'
WHEN 2 THEN 'NONCLUSTERED'
WHEN 3 THEN 'XML'
ELSE 'UNKNOWN' END AS [Index Type],
CASE
WHEN (i.[is_primary_key]) = 1 THEN 'PRIMARY KEY'
WHEN (i.[is_unique]) = 1 THEN 'UNIQUE'
ELSE '' END AS [Constraint Type],
CASE
WHEN (i.[is_unique_constraint]) = 1
OR (i.[is_primary_key]) = 1
THEN 'CONSTRAINT'
WHEN i.[type] = 0 THEN 'HEAP'
WHEN i.[type] = 3 THEN 'XML INDEX'
ELSE 'INDEX' END AS [Object Type],
(SELECT COALESCE(c1.[name],'') _
FROM [sys].[columns] AS c1 INNER JOIN [sys].[index_columns] AS ic1
ON c1.[object_id] = ic1.[object_id] AND c1.[column_id] = ic1.[column_id] AND ic1.[key_ordinal] = 1
WHERE ic1.[object_id] = i.[object_id] AND ic1.[index_id] = i.[index_id]) +
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+ o.[name] +
']', i.[index_id], 2) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' +
u.[name] + '].['+ o.[name] + ']', i.[index_id],2) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id], 3) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],3) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id], 4) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],4) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 5) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],5) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id], 6) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],6) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id], 7) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id], 7) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],8) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],8) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 9) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],9) END +
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 10) IS NULL THEN ''
ELSE ', '+INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],10) END AS [ColName],
(SELECT COALESCE(c1.[name],'') FROM [sys].[columns]
AS c1 INNER JOIN [sys].[index_columns] AS ic1
ON c1.[object_id] = ic1.[object_id]
AND c1.[column_id] = ic1.[column_id] AND ic1.[key_ordinal] = 1
WHERE ic1.[object_id] = i.[object_id]
AND ic1.[index_id] = i.[index_id]) AS [ColName1],
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 2) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],2) END AS [ColName2],
CASE
WHEN INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id], 3) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],3) END AS [ColName3],
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 4) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],4) END AS [ColName4],
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 5) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],5) END AS [ColName5],
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 6) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],6) END AS [ColName6],
CASE
WHEN INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id], 7) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],7) END AS [ColName7],
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id],8) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],8) END AS [ColName8],
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 9) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],9) END AS [ColName9],
CASE
WHEN INDEX_COL('[' + u.[name] + '].['+
o.[name] + ']', i.[index_id], 10) IS NULL THEN ''
ELSE INDEX_COL('[' + u.[name] + '].[' +
o.[name] + ']', i.[index_id],10) END AS [ColName10]
FROM [sys].[objects] AS o WITH (NOLOCK)
LEFT OUTER JOIN [sys].[indexes] AS i WITH (NOLOCK)
ON o.[object_id] = i.[object_id]
JOIN [sys].[schemas] AS u WITH (NOLOCK)
ON o.[schema_id] = u.[schema_id]
LEFT OUTER JOIN sys.dm_db_partition_stats AS p
WITH (NOLOCK) ON i.index_id = p.index_id and i.object_id = p.object_id
WHERE o.[type] = 'U'
AND o.[name] NOT IN ('dtproperties')
AND i.[name] NOT LIKE '_WA_Sys_%'
-----------
SELECT 'Listing Possible Redundant Index keys' AS [Comments]
SELECT DISTINCT I.[Table Name], I.[Index Name] ,
I.[Index Type], I.[Constraint Type], I.[ColName]
FROM @AllIndexes AS I
JOIN @AllIndexes AS I2
ON I.[Table ID] = I2.[Table ID]
AND I.[ColName1] = I2.[ColName1]
AND I.[Index Name] <> I2.[Index Name]
AND I.[Index Type] <> 'XML'
ORDER BY I.[Table Name], I.[ColName]
----------
SELECT 'Listing Possible Reverse Index keys' AS [Comments]
SELECT DISTINCT I.[Table Name], I.[Index Name],
I.[Index Type], I.[Constraint Type], I.[ColName]
FROM @AllIndexes AS I
JOIN @AllIndexes AS I2
ON I.[Table ID] = I2.[Table ID]
AND I.[ColName1] = I2.[ColName2]
AND I.[ColName2] = I2.[ColName1]
AND I.[Index Name] <> I2.[Index Name]
AND I.[Index Type] <> 'XML'
Output
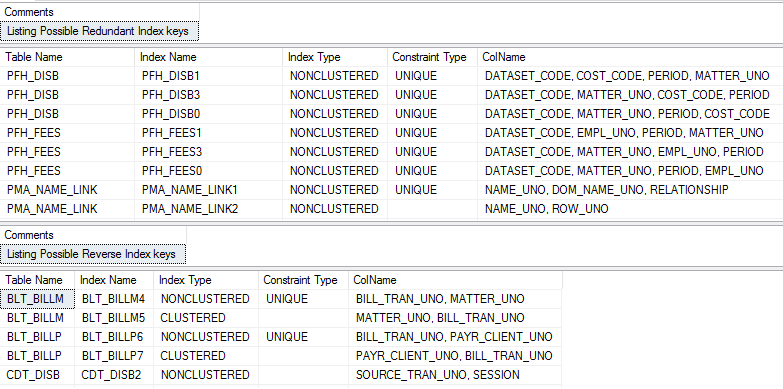
Finding and removing duplicate indexes, that is, multiple indexes created on the same set of columns is an excellent way to remove bottlenecks. Such indexes provide no additional benefit but use up extra disk space and might hinder performance of INSERT, UPDATE and DELETE statements.
References
https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-indexes-transact-sql
https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-db-index-usage-stats-transact-sql
https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-index-columns-transact-sql