

One very important design aspect when creating a new table is the decision to create or not create a clustered index. A table that does not have a clustered index is referred to as a HEAP and a table that has a clustered index is referred to as a clustered table. A clustered table provides benefits over a heap such as physically storing the data based on the clustered index, the ability to use the index to find the rows quickly and the ability to reorganize the data by rebuilding the clustered index.
This article summarizes the advantages and disadvantages, the difference in performance characteristics, and other behaviours of tables that are ordered as lists (clustered indexes) or heaps.
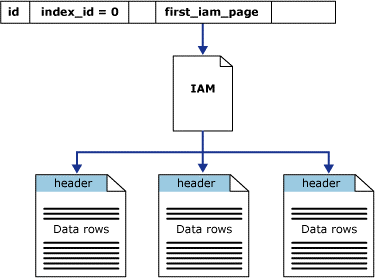
HEAP
- Data is not stored in any particular order. They’re scattered on disk anywhere that SQL Server can find a spot.
- Specific data cannot be retrieved quickly, unless there are also non-clustered indexes.
- Data pages are not linked, so sequential access needs to refer back to the index allocation map (IAM) pages.
- Since there is no clustered index, additional time is not needed to maintain the index.
- Since there is no clustered index, there is not the need for additional space to store the clustered index tree
- These tables have a index_id value of 0 in the sys.indexes catalog view
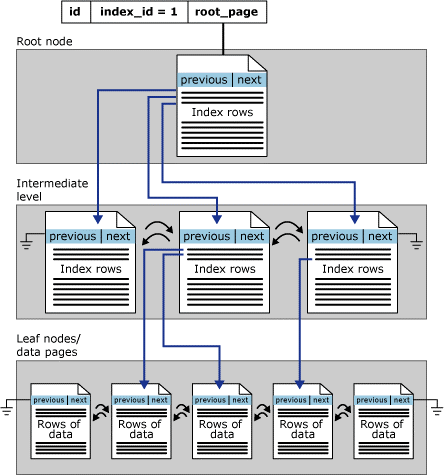
Clustered Table
- Data is stored in order based on the clustered index key.
- Data can be retrieved quickly based on the clustered index key, if the query uses the indexed columns.
- Data pages are linked for faster sequential access.
- Additional time is needed to maintain clustered index based on INSERTS, UPDATES and DELETES.
- Additional space is needed to store clustered index tree.
- These tables have a index_id value of 1 in the sys.indexes catalog view.
When a table is created as a heap, SQL Server does not force where the new data pages are written. Whenever new data is written this data is always written at the end of the table or on the next available page that is assigned to this table. When data is deleted the space becomes free in the data pages, but it is not reused because new data is always written to the next available page.
With a clustered index, depending on the index key, new records may be written to existing pages where free space exists or there may be need to split a page into multiple pages in order to insert the new data. When deletes occur the same issue occurs as with a heap, but this free space may be used again if data needs to be inserted into one of the existing pages that has free space.
Tests
The objective of our testing was to characterize the performance and behaviour of DML operations performed against the same set of table data organized:
- As a heap with a non-clustered index on a specified set of column(s).
- With a clustered index on the same set of column(s), and no other non-clustered index on the same set of column(s).
INSERT Performance
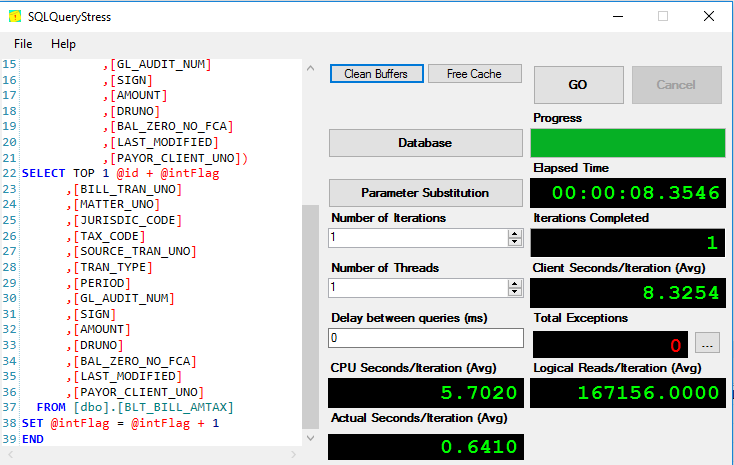
Let’s test a heap [dbo].[BLT_BILL_AMTAX] in our Allens Database. It has a non-clustered index on ROW_UNO primary key column.
I have executed a query which will inserts 10000 records (one record at a time) in to the heap and recorded the results as shown below.
Let’s drop the existing non-clustered index on ROW_UNO primary key column and create a new clustered index on ROW_UNO primary key column as shown below.
USE [Allens] GO ALTER TABLE [dbo].[BLT_BILL_AMTAX] DROP CONSTRAINT [BLT_BILL_AMTAX3] GO ALTER TABLE [dbo].[BLT_BILL_AMTAX] ADD CONSTRAINT [BLT_BILL_AMTAX3] PRIMARY KEY CLUSTERED ( [ROW_UNO] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
I have executed the same query which will inserts 10000 records (one record at a time) in to the clustered table and recorded the results as shown below.
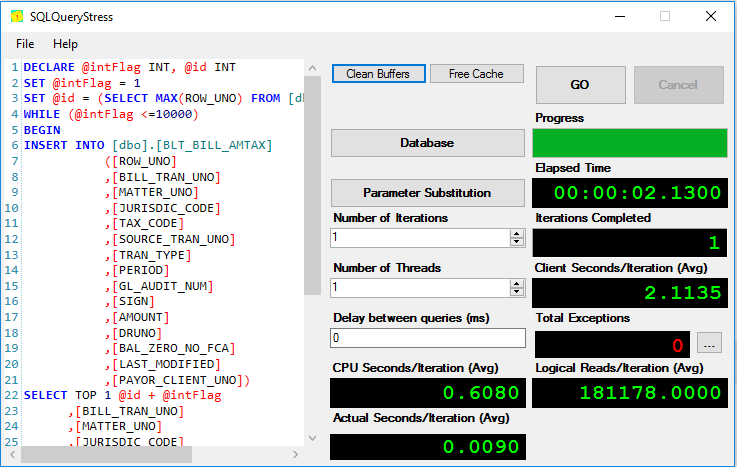
From our tests, we can clearly observe that inserting data into a table with a clustered index was faster than inserting the same data into the table with just a non-clustered index (heap).
UPDATE Performance
This test attempts to measure the performance difference in performing row-by-row updates on a table with a clustered index and one with just a non-clustered index (heap) on the same columns. For each update operation, only a single row of data in the target table was updated.
This test measures the performance of updating a non-indexed column (JURISDIC_CODE) in the [dbo].[BLT_BILL_AMTAX] table.
UPDATE [dbo].[BLT_BILL_AMTAX] SET JURISDIC_CODE = 'AU' WHERE ROW_UNO = 767103
For the table with the clustered index, an update operation involves searching for the row to update by traversing the clustered index B-tree, and then changing the value of the column(s) to be updated. For a table with a non-clustered index, an update operation involves searching for the row to update by traversing the clustered index B-tree, followed by locating the page in the table that contains the corresponding row, and then changing the value of the column(s) to be updated.
For UPDATE operations on non-indexed columns, a table with a clustered index outperforms a table with non-clustered index. This is because the update operation on a table with a clustered index requires much less work to be performed than on a table with a non-clustered index.
As indicated in the execution plan in Figure 1, in the case of a clustered index, updating a row requires a single index seek operation followed by an update of the data row (leaf node of the index).
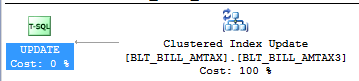
Figure 1: Execution plan for UPDATE operation on table with clustered index
The corresponding UPDATE operation on a table with a non-clustered index results in a seek operation using the non-clustered index, a dereference using the RID (row identifier) to locate the corresponding data row, followed by update of the data row, as indicated by the execution plan in Figure 2.

Figure 2: Execution plan for UPDATE operation on table with non-clustered index
The extra work required to update a row when using a non-clustered index as compared to using a clustered index explains the performance difference. Based on this test result, we concluded that for update operations it is advantageous to have a clustered index on a table.
DELETE Performance
This test attempts to measure the performance difference in performing row-by-row deletes on a table with a clustered index and one with just a non-clustered index (heap) on the same columns. For each delete operation, only a single row of data in the target table is deleted.
This test measures the performance of deleting a record in the [dbo].[BLT_BILL_AMTAX] table.
DELETE [dbo].[BLT_BILL_AMTAX] WHERE ROW_UNO = 767103
For a table with a clustered index, a delete operation, based on predicates on the indexed columns, results in a single index seek operation followed by deleting the data row. The corresponding delete operation in a table with a non-clustered index, results in a seek operation using the non-clustered index, a dereference using the RID (row identifier) to locate the corresponding data row, followed by the actual delete. In addition, the corresponding entry from the non-clustered index B-tree must be removed as well.
A delete operation involves locating the set of data rows and consequently deleting the row. In the case of the table with the clustered index, the database engine performed a SEEK into the table and deleted the row by using a single ‘Clustered Index Delete’ operation. This is shown in the query execution plan in Figure 3.
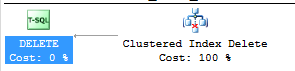
Figure 3: Execution plan for DELETE operation on table with clustered index
For the table with the non-clustered index, the data row had to first be located by using an index seek operation followed by a Table Delete operation, which involves removing the actual row as well as the entry from the non-clustered index B-tree. This is shown in the query execution plan in Figure 4.

Figure 4: Execution plan for DELETE operation on table without a clustered index
Given the additional operations that needed to be performed, we can clearly observe the performance of deleting values on a table with a clustered index to be faster than performing the same operation on a table with a non-clustered index.
SELECT Performance
This test measures the performance difference between performing single-row selects on a table with a clustered index and one with just a non-clustered index (heap) on the same columns. Each select operation returns only a single row of data from the table.
This test measures the performance of selecting a record in the [dbo].[BLT_BILL_AMTAX] table.
SELECT * FROM [dbo].[BLT_BILL_AMTAX] WHERE ROW_UNO = 767103
For the table with the clustered index, a select operation, based on the predicates on the indexed columns, results in an index seek operation, which then yields the data values requested. The corresponding select operation on a table without a clustered index results in a seek operation using the non-clustered index, followed by nested loop join with the table to extract the columns not in the index definition (assuming the index is not a covering index for the given query), which then yields the requested row.
A select operation involves the search for one or more rows from a table. In the table with a clustered index, the database engine performs a Clustered Index Seek operation into the table and yields the requested data row. This is shown in the query execution plan in Figure 5.

Figure 5: Execution plan for SELECT operation on table with clustered index
For the table with the non-clustered index, the data row had to first be located by using an Index Seek operation with the non-clustered index, followed by Nested Loops (Inner Join) with a RID (row identifier) Lookup to extract the set of selected columns that were not a part of the non-clustered index. This is shown in the query execution plan in Figure 6.
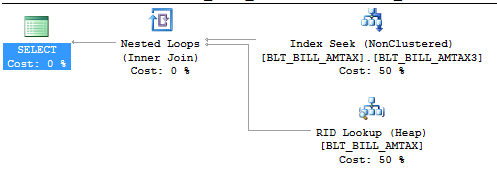
Figure 6: Execution plan for SELECT operation on table with non-clustered index
Given the additional processing that needed to be done, we can clearly observe that the performance of selecting rows from a table with a clustered index to be faster than performing the same operation on a table with a non-clustered index.
Solution
This isn’t a fast fix: we need to do some research and design. We’ll need to:
- List the heaps (tables with no clustered indexes)
- If they’re being actively queried, determine the right clustering index. Sometimes there’s already a primary key, but someone just forgot to set it as the clustered index.
After the change, you can monitor overall system performance looking for improvements, especially around query execution plans and lower logical reads.
References
https://msdn.microsoft.com/en-us/library/ms188270.aspx
https://msdn.microsoft.com/en-us/library/ms177443.aspx
https://msdn.microsoft.com/en-us/library/ms177484.aspx
